مقدمة عن الصوت الرقمي
الصوت الرقمي
كل الأصوات التي نسمعها بآذاننا هي موجات ضغط تنتقل عبر الهواء, من الممكن التقاط وتسجيل هذه الموجات على وسط مادي ثم إعادة إنتاجها لاحقًا . تبدو موجات ضغط الصوت أو الأشكال الموجية Waveform كما يلي:
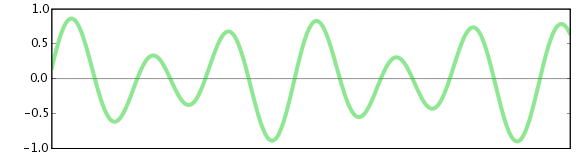
تقوم وسائط التسجيل التناظرية (التماثلية) Analogue مثل تسجيلات الفونوغراف وأشرطة الكاسيت بتسجيل شكل الموجة كما هو ، باستخدام عمق الأخدود للتسجيل (في الاسطوانات ) أو مقدار المغناطيسية للشريط الكاسيت. يمكن أن ينتج عن التسجيل التناظري مجموعة رائعة من الأصوات ، ولكنه يعاني أيضًا من مشاكل الضوضاء والضجيج المصاحب في التسجيل و التشغيل. والجدير بالذكر أنه في كل مرة يتم فيها نسخ تسجيل تمثيلي ، يتم إدخال المزيد من الضوضاء، مما يقلل من الدقة. يمكن تقليل هذه الضوضاء ولكن لا يمكن إزالتها تمامًا.
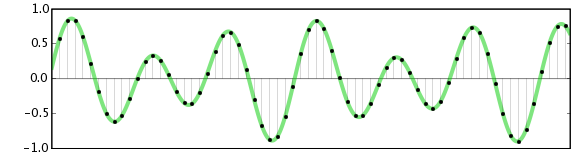
يعمل التسجيل الرقمي Digital recording بشكل مختلف: فهو يأخذ عينات من شكل الموجة في نقاط زمنية متباعدة بشكل متساوٍ، ومن ثم يمثل كل عينة كرقم دقيق. التسجيلات الرقمية، سواء كانت مخزنة على قرص مضغوط (CD) أو شريط صوتي رقمي (DAT) أو على جهاز كمبيوتر شخصي ، لا تتغير و تحافظ على قيمتها بمرور الوقت ولا تتخامد وتتشوه كما في التسجيل التماثلي, كما ان التسجيلات الرقمية يمكن نسخها بشكل مثالي دون ادخال أي ضوضاء إضافية. توضح الصورة التالية نموذجًا موجيًا صوتيً تلاحظ فيه كيف يتم أخذ عينات من الموجة الصوتية:
جودة الصوت الرقمي
تعتمد جودة التسجيل الصوتي الرقمي بشكل كبير على عاملين: رئيسيين الاول هو معدل العينة Sample Rate والثاني هو تنسيق العينة Sample format أو عمق البت Bit depth .
تؤدي زيادة معدل العينة أو عدد البتات في كل عينة إلى زيادة جودة التسجيل ، ولكنها تزيد أيضًا من مقدار المساحة التي تستخدمها ملفات الصوت على الكمبيوتر أو القرص او الوسائط التي يتم تخزين الملفات فيها.
معدلات العينة Sample Rate
تُقاس معدلات العينة بالهرتزHz ، أو عدد الموجات في الثانية. Cycle per second هذه القيمة هي عدد العينات الملتقطة في الثانية لتمثيل شكل الموجة. تسمح معدلات العينة الأعلى بتمثيل ترددات صوتية الأعلى, شريطة أن يكون معدل العينة أكثر من ضعف أعلى تردد صوتي موجود ، يمكن إعادة بناء شكل الموجة بالضبط من العينات الرقمية.
لا يمكن تمثيل الترددات التي تزيد عن نصف معدل العينة بشكل صحيح في العينات الرقمية ، وإذا كانت موجودة في الصوت الأصلي ، فيجب إزالتها قبل التحويل إلى رقمي. وبالتالي فإن “نصف معدل العينة” يمثل حدًا أعلى يسمى تردد نيكويست، ويجب أن يكون شكل الموجة التناظرية أقل تمامًا من هذا الحد حتى يتم تمثيلها رقميًا بشكل صحيح. لا يمكن تمثيل الترددات التناظرية عند هذا الحد أو أعلى بشكل صحيح بواسطة العينات الرقمية وقد تسبب نوعًا من التشويه يسمى التعرج Aliasing.
الأذن البشرية حساسة للصوت بترددات تقع بين 20 هرتز و 20000 هرتز تقريبًا. الأصوات خارج هذا النطاق غير مسموعة, ذلك فإن معدل العينة Sample rate يجب ان يكون على الاقل 40.000 هرتز هو الحد الأدنى المطلق الضروري لإعادة إنتاج النطاق الكامل للأصوات المسموعة. عادةً ما يتم استخدام معدل عينات من هذا الرقم وتسمى Oversampling لتجنب حدوث التعرج aliasing.
معدل العينة المستخدم بواسطة الأقراص الصوتية المضغوطة هو 44100 هرتز, مع ملاحظة أن الكلام البشري واضح حتى لو تم التخلص من الترددات التي تزيد عن 4000 هرتز, حتى أن الهواتف لا ترسل إلا الترددات التي تقع بين 200 هرتز و 4000 هرتز. لذلك ، فإن معدل العينة الشائع للتسجيلات الصوتية هو 8000 هرتز ، وهو ما يسمى أحيانًا بجودة الكلام . Speech Quality
معدلات العينة الأكثر شيوعًا المقاسة بالهرتز هي 8000 و 16000 و 22050 و 44100 و 48000 و 96000 و 192000. يمكن أيضًا الإشارة إلى معدلات العينة بوحدات كيلو هرتز . لذلك ، في وحدات كيلوهرتز ، يتم التعبير عن المعدلات الأكثر شيوعًا على أنها 8 كيلوهرتز و 16 كيلوهرتز و 22.05 كيلوهرتز و 44.1 كيلوهرتز و 48 كيلوهرتز و 96 كيلوهرتز و 192 كيلوهرتز.
معظم بطاقات صوت الكمبيوتر تقتصر على معدلات عينات 48000 هرتز أو 96000 هرتز أو في بعض الأحيان 192000 هرتز. ولكن معدل العينة الأكثر شيوعًا حتى الآن هو 44100 هرتز ، وبالتالي فإن العديد من البطاقات ستتخلف عن هذا المعدل ، بغض النظر عن المعدلات الأخرى التي تدعمها.
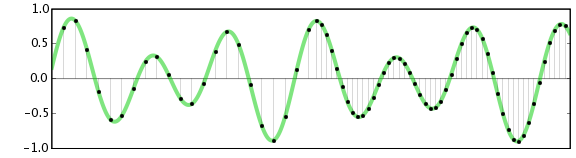
في الصورة أدناه ، النصف الأيسر لديه معدل عينة منخفض ، والنصف الأيمن لديه معدل عينة مرتفع أي دقة عالية:
نماذج التنسيقات Sample formats
المقياس الآخر لجودة الصوت الرقمي هو تنسيق العينة (أو عمق البت bit depth ) والذي يقاس عادةً بعدد بتات الكمبيوتر المستخدمة لتمثيل كل عينة. كلما زاد عدد البتات المستخدمة ، زادت دقة تمثيل كل عينة, تؤدي زيادة عدد البتات أيضًا إلى زيادة النطاق الديناميكي الأقصى للتسجيل الصوتي ، أي الاختلاف في مستوى الصوت بين أعلى وأنعم الأصوات الممكنة التي يمكن تمثيلها.
النطاق الديناميكي يقاس بالديسيبل dB يمكن للأذن البشرية إدراك الأصوات بمدى ديناميكي لا يقل عن 90 ديسيبل. ومع ذلك ، كلما كان ذلك ممكنًا ، من الجيد تسجيل صوت رقمي بنطاق ديناميكي يزيد عن 90 ديسيبل ، جزئيًا بحيث يمكن تضخيم الأصوات الضعيفة جدًا لتحقيق أقصى قدر من الدقة. لاحظ أنه على الرغم من أنه يمكن رفع مستوى الإشارات المسجلة عند مستويات منخفضة بشكل عام للاستفادة من النطاق الديناميكي المتاح فإن تسجيل إشارات المستوى المنخفض لن يستخدم كل (عمق البت)
تتضمن تنسيقات النماذج sample formats الشائعة والنطاق الديناميكي الخاص بها ما يلي:
- § 8 بت: 48 ديسيبل
- § 16 بت: 96 ديسيبل
- § 24 بت: 145 ديسيبل
- نقطة عائمة 32 بت: ديسيبل غير محدود تقريبا
لاحظ أن هناك قيودًا عملية على النطاق الديناميكي بسبب قدرات الأجهزة ومحولات الإدخال والإخراج. هذه تجعل الحد العملي مثل 90 ديسيبل لـ 16 بت.
هناك نماذج تنسيقات Sample rate مثل ADPCM تقريبية لصوت 16 بت مع عينات مضغوطة 4 بت. ولكن نادرًا ما يتم استخدامها بسبب أساليب الضغط Compression الحديثة الأفضل .
تستخدم الأقراص الصوتية المضغوطة ومعظم تنسيقات الملفات الصوتية للكمبيوتر 16 بت
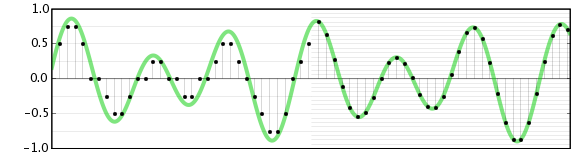
في الصورة أدناه ، يحتوي النصف الأيسر على (عمق بت) او تنسيق عينة sample format مع عدد قليل من البتات ، بينما يحتوي النصف الأيمن على تنسيق عينة به مزيد من البتات. يمكنك اعتبار أن معدل العينة Sample rate هو التباعد بين خطوط الشبكة العمودية في الشكل، بينما تنسيق العينة هو التباعد بين خطوط الشبكة الأفقية.
حجم ملفات الصوت
ملفات الصوت كبيرة جدًا وتحتوي على مجموعة من البيانات كبيرة ، (ولكتها تظل أقل من ملفات الفيديو)
. لحساب حجم ملف صوتي نضرب معدل العينة (على سبيل المثال 44100 هرتز) في معدل بت تنسيق العينة (على سبيل المثال 16 بت) في عدد القنوات (2 للستيريو) في عدد الثواني
. يستغرق قرص CD ستريو كامل مدته 74 دقيقة أكثر من 6 مليارات بت. نقسّم هذا العدد على 8 لنحصل على عدد البايتات ؛ القرص المضغوط الصوتي أقل بقليل من 800 ميغا بايت
القص Clipping
يتمثل أحد قيود الصوت الرقمي بأنه لا يمكنه التعامل مع موجات ضغط الصوت Sound pressure level التي تتجاوز المستويات القصوى المصممة للتعامل معها. عندما يتم تسجيل إشارة تتجاوز المستوى الأقصى +/- 1.0 خطي أو 0 ديسيبل ، يتم قطع العينات خارج النطاق إلى القيمة القصوى كما هو موضح بالشكل التالي:
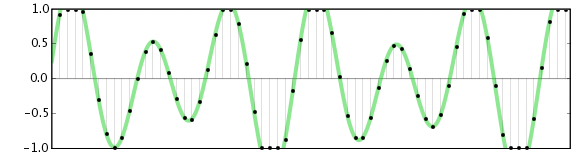
سيبدو الصوت المسجل بالقطع مشوهًا في حين أن هناك بعض التقنيات التي يمكن أن تقضي على قدر ضئيل من الضوضاء بسبب هذا القطع ، فمن الأفضل دائمًا تجنب القص أثناء التسجيل لهذا عليك ان تقوم بتغيير مستوى الصوت في مصدر الاشارة (ميكروفون ، مشغل كاسيت ، مشغل أسطوانات)
صوت مضغوط Compressed Audio
نظرًا لأن ملفات الصوت الرقمية كبيرة جدًا ، فقد تم استخدام معدلات عينات مخفضة كلما أمكن ذلك. في عام 1991 ، تم اختيار ما يسمى MP3 ، وهي تقنية ضغط للبيانات او تقليل حجم البيانات عبر الغاء جزء البيانات التي يمكن أن تقلل بشكل كبير من حجم ملف الصوت الرقمي مع تأثير ضئيل على الجودة.
تستغرق ثانية واحدة من الصوت بجودة CD حوالي 1.4 ميغا بت ، في حين أن معدل البت الشائع لملفات MP3 هو 128 كيلوبت في الثانية ، وهو عامل ضغط يزيد عن عشر مرات, يعمل MP3 عن طريق “التخلص” بذكاء من التفاصيل حول شكل الموجة الصوتية التي لا يشعر بها البشر ، استنادًا إلى نموذج صوتي كيفية معالجة آذاننا وأدمغتنا للأصوات. لا يتم إنشاء جميع ملفات MP3 على حد سواء ؛ ستؤدي النماذج الصوتية المختلفة إلى كميات مختلفة من التشويه الملحوظ في الملف الصوتي.
يمكن للجرأة كما تم شحنها استيراد وتصدير ملفات MP3.
عندما يتم استخدام سماعة صوت عالية الجودة يمكن لمعظم الناس سماع الفرق بين ملف صوتي مسجل بتقنية MP3 128 كيلوبت في الثانية وملف صوتي غير مضغوط من CD,
ضغط بلا خسائر Lossless Compression
يعمل الضغط بدون فقدان البيانات على تقليل حجم الملف دون فقدان الجودة. يمكن تطبيق هذه الطريقة السحرية لتقليل أحجام الملفات على ملفات الصوت. بينما تستخدم ملفات MP3 ضغطًا مع فقدان البيانات ، يمكن استخدام خوارزميات ضغط أحدث ، مثل FLAC و Apple Lossless ، لإنشاء ملفات صوتية مضغوطة بدون فقدان.
يؤدي هذا الضغط بشكل أساسي إلى إعادة كتابة بيانات الملف الأصلي بطريقة أكثر فاعلية. ومع ذلك ، نظرًا لعدم فقدان الجودة ، تكون الملفات الناتجة عادةً أكبر بكثير من ملفات الصوت المضغوطة بصيغ MP3 .
على سبيل المثال ، قد يكون حجم الملف المضغوط باستخدام الضغط مع فقدان البيانات عُشر حجم الملف الأصلي ، بينما من غير المحتمل أن ينتج عن الضغط بدون فقدان ملف أصغر من نصف الحجم الأصلي.
غالبًا ما تُستخدم تنسيقات الصوت بدون فقدان البيانات لأغراض الأرشفة أو الإنتاج ، بينما تُستخدم ملفات الصوت التي لا تحتوي على فقدان أصغر عادةً على مشغلات الصوت المحمولة وفي حالات أخرى تكون فيها مساحة التخزين محدودة أو يكون النسخ المتماثل الدقيق للصوت غير ضروري.
م. سعيد سليمان
هذه المقالة هي ترجمة بتصرف من موقع Audacity للاطلاع على المقالة الاصلية اضغط هنا